
Research:
I am an alumnus of the Indiana Center for Database Systems (ICDS) and Microsoft® Research. My current research interests lie in the areas of cloud computing, data management and mining, and security engineering. I had the chance to work with researchers from several other disciplines, including computer networks, theory, biology (EcoliHub project), and library sciences. (Yes, I can speak with biologists and librarians!). Below is a summary of some research projects I am involved in.
Ideas for MS projects
- Implement a spatial operator inside SpatialHadoop (e.g., rNN, GNN, ANN, ...)
- Build a credibility model for news sources.
Massively Parallel Processing of Spatio-temporal Queries
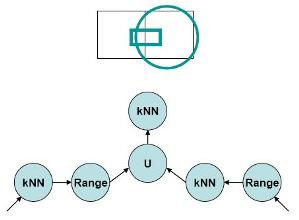
Location-detection devices are used ubiquitously in moving objects due to the everyday decreasing cost and simplified technology. Usually, these devices will send the moving objects’ location information to a spatio-temporal data stream management system that will be then responsible for answering spatio-temporal queries related to these moving objects. Most of the existing work focused on the continuous spatio-temporal query execution. However, several outstanding challenges have been either addressed partially or not at all in the existing literature. In this project, we propose the adaptive massively-parallel execution of the continuous queries for spatio-temporal data stream management systems. In addition, query optimization techniques are proposed for executing multi-predicate spatio-temporal queries on moving objects. In particular, we provide a costing mechanism for continuous spatio-temporal queries. We provide for the optimization of the parameters of the spatiotemporal operators.
Business-Driven Software Security Engineering
With software pervading many aspects of business and personal life, security has emerged as a key challenge for engineering software. Security is usually considered after the fact and often in an ad-hoc manner leading to structural and functional vulnerabilities in software and subsequent risks and losses to organizations. The lack of a systematic procedure for analyzing and modeling the business security aspects while propagating them to later stages of software development remains a major challenge in engineering trusted software. We propose a systematic business-driven platform for developing secure software that allows for modeling business security aspects while propagating the business security properties to the software development life cycle. The proposed platform effectively extends the standard Business Process Modeling Notations (BPMN) adopted by the Object Management Group (OMG) with explicit security behavior. Further, the proposed platform propagates the business security aspects and behavior to the object-oriented requirements, analysis and design phases in Unified Modeling Language (UML) through means of systematic transformations.
Chameleon: Context Awareness inside DBMSs

Context is any information used to characterize the situation of an entity. Examples of contexts include time, location, identity, and activity of a user. This project proposes a general context-aware DBMS, named Chameleon, that will eliminate the need for having specialized database engines, e.g., spatial DBMS, temporal DBMS, and Hippocratic DBMS, since space, time, and identity can be treated as contexts in the general context-aware DBMS.
In Chameleon, we can combine multiple contexts into more complex ones using the proposed context composition, e.g., a Hippocratic DBMS that also provides spatio-temporal and location contextual services. As a proof of concept, we construct two case studies using the same context-aware DBMS platform within Chameleon. One treats identity as a context to realize a privacy-aware (Hippocratic) database server, while the other treats space as a context to realize a spatial database server using the same proposed constructs and interfaces of Chameleon.
Lazy Maintenance of Materialized Views
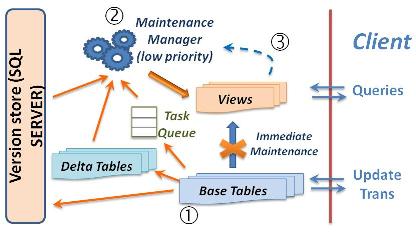
Materialized views can speed up query processing greatly but they have to be kept up to date to be useful. Today, database systems typically maintain views eagerly in the same transaction as the base table updates. This has the effect that updates pay for view maintenance while beneficiaries (queries) get a free ride! View maintenance overhead can be significant and it seems unfair to have updates bear the cost.
We present a novel way to lazily maintain materialized views that relieves updates of this overhead. Maintenance of a view is postponed until the system has free cycles or the view is referenced by a query. View maintenance is fully or partly hidden from queries depending on the system load. Ideally, views are maintained entirely on system time at no cost to updates and queries. The efficiency of lazy maintenance is improved by combining updates from several transactions into a single maintenance operation, by condensing multiple updates of the same row into a single update, and by exploiting row versioning. Experiments using a prototype implementation in Microsoft SQL Server show much faster response times for updates and also significant reduction in maintenance cost when combining updates.
Spatio-temporal Selectivity Estimation
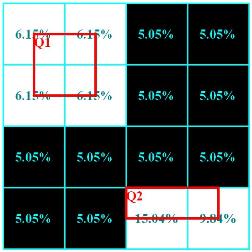
We present a framework for building and continuously maintaining spatio-temporal histograms (ST-Histograms). ST-Histograms are used for selectivity estimation of continuous pipelined query operators. Unlike traditional histograms that examine and/or sample all incoming data tuples, ST-Histograms are built by monitoring the actual selectivities of the outstanding continuous queries. ST-Histograms have three main features: (1) The ST-Histograms are built with (almost) no overhead to the system. We use only feedback (i.e., the actual selectivity) from the existing continuous queries. (2) Rather than wasting system resources in maintaining accurate histograms for the whole spatial space, we only maintain accurate histograms for that part of the space that is relevant to the current existing queries. The rest of the space has less accurate histograms. (3) The ST-Histograms are equipped with a periodicity detection procedure that predicts the future execution of the continuous queries. Hence, the query processing engine can continuously adapt the continuous query pipeline to reflect this prediction.
Adaptive Processing of Ranking Queries:
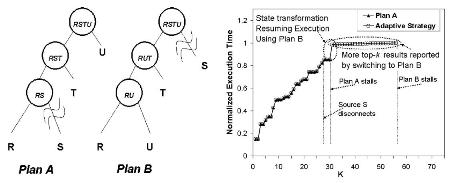
Fluctuations and continuous changes in system parameters are distinguishing characteristics in modern computing environments. Optimal execution strategies picked by static query optimizers usually lose their optimality due to these inevitable changes. Hence, adaptive query processing is a key requirement in almost all modern applications. In this project, we introduce several adaptive processing techniques for ranking and top-k queries that are dominant in many emerging applications. Ranking queries pose many challenges not handled by current proposed adaptive query processing techniques. For example, top-k query plans are usually pipelined and maintain complex ranking state. Altering the execution strategy of a running ranking query is a non-trivial task.
Using a current real-world query processing and optimization framework, we introduce a novel mid-query re-optimization algorithm for ranking queries. The proposed algorithm alters the pipelined evaluation plan in run-time, and allows for resuming execution with an optimal (or better) execution strategy. We employ an aggressive reuse of the existing computation state to minimize the re-optimization overhead.
Secure Supply-Chain Protocols
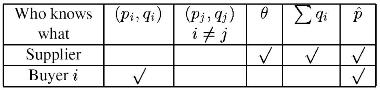
Supply chain interactions have huge economic importance, yet these interactions are managed inefficiently. One of the major sources of inefficiency in supply-chain management is information asymmetry; i.e., information that is available to one or more organizations in the chain (e.g., manufacturer, retailer) is not available to others. There are several causes of information asymmetry, among them fear that a powerful buyer or supplier will take advantage of private information, that information will leak to a competitor, etc. We propose Secure Supply-Chain Collaboration (SSCC) protocols that enable supply-chain partners to cooperatively achieve desired system-wide goals without revealing the private information of any of the parties, even though the jointly-computed decisions require the information of all the parties. Secure supply-chain collaboration has the potential to improve supply-chain management practice, and, by removing one major inefficiency therein, improve productivity. We present specific SSCC protocols for two types of supply-chain interactions: Capacity allocation, and e-auctions. In the course of doing so, we design techniques that are of independent interest, and are likely to be useful in the design of future SSCC protocols.